Motivation;
Whenever we will hear about Big Data implementation and its tools, we would definitely hear about Hadoop community.
According to IBM analytics, some companies are delaying data opportunities because of organizational constraints. Others are not sure what distribution to choose and still, others simply can’t find time to mature their Big Data delivery due to the pressure of day to day business needs.
Hadoop is an open-source software framework used to store and process huge amounts of data. It is implemented in several distinct, specialized modules;
- Storage, principally employing the Hadoop File System or HDFS.
- Resource management and scheduling for computational tasks.
- Distributed processing programming model based on MapReduce.
- Common utilities and software libraries necessary for the entire Hadoop platform.
What is Hadoop?
Let’s say a scenario:
- We have 1GB of data that you need to process. The data is stored in a relational database in your desktop computer which has no problem handling the load.
- Then our company starts growing very quickly, and that data grows to 10GB, then 100GB, And we start to reach the limits of your current desktop computer.
- so what do we do?
- We scale up by investing in a larger computer, and we are then OK for a few more months.
- Similarly, when our data grows from 1 TB to 10TB, and then 100TB, we are again quickly approaching the limits of that computer.
- Moreover, we are now asked to feed the application with unstructured data coming from sources like Facebook, Twitter, RFID readers, sensors, and so on.
- The management wants to derive information from both the relational data and the unstructured data and wants this information as soon as possible
So, What should you do now? Well, Hadoop may be the answer!
What is Hadoop? Hadoop is an open source project of the Apache Foundation.
- It is a framework written in Java originally developed by Doug Cutting who named it after his son’s toy elephant.
- Hadoop uses Google’s MapReduce technology as its foundation.
- It is optimized to handle massive quantities of data which could be structured, unstructured or semi-structured, using commodity hardware, that is, relatively inexpensive computers.
- This massively parallel processing is done with great performance. However, it is a batch operation handling massive amounts of data, so the response time is not immediate.
- Currently, in place updates are not possible in Hadoop, but appends to existing data is supported.
Now, what’s the value of a system if the information it stores or retrieves is not consistent? Hadoop replicates its data across different computers so that if one goes down, the data is processed on one of the replicated computers.
- Hadoop is not suitable for OnLine Transaction Processing workloads where data is randomly accessed on structured data like a relational database.
- Also, Hadoop is not suitable for OnLine Analytical Processing or Decision Support System workloads where data is sequentially accessed on structured data like a relational database, to generate reports that provide business intelligence.
Hadoop is used for Big Data.
- It compliments OnLine Transaction Processing and Online Analytical Processing.
- It is NOT a replacement for a relational database system.
So, what is Big Data? With all the devices available today to collect data, such as RFID readers, microphones, cameras, sensors, and so on, we are seeing an explosion in data being collected worldwide. Big Data is a term used to describe large collections of data (also known as datasets) that may be unstructured, and grow so large and quickly that it is difficult to manage with a regular database or statistical tools.
In terms of numbers, what are we looking at? How BIG is “big data”?
- There are more than 3.2 billion internet users.
- Active cell phones have surpassed 7.6 billion.
- There are now more in-use cell phones than there are people on the planet (7.4 billion).
- Twitter processes 7TB of data every day,
- 600TB of data is processed by Facebook every day.
- Interestingly, about 80% of this data is unstructured.
With this massive amount of data, businesses need fast, reliable, deeper data insight. Therefore, Big Data solutions based on Hadoop and other analytics software are becoming more and more relevant.
Tools Related to Hadoop
This is a list of some other open source project related to Hadoop:
- Eclipse is a popular IDE donated by IBM to the open-source community
- Lucene is a text search engine library written in Java
- Hbase is a Hadoop database
- Hive provides data warehousing tools to extract, transform and load (ETL) data, and query this data stored in Hadoop files
- Pig is a high level language that generates MapReduce code to analyze large data sets.
- Spark is a cluster computing framework.
- ZooKeeper is a centralized configuration service and naming registry for large distributed systems
- Ambari manages and monitors Hadoop clusters through an intuitive web UI
- Avro is a data serialization system – UIMA is the architecture for the development, discovery, composition and deployment for the analysis of unstructured data.
- Yarn is a large-scale operating system for big data applications
- Mapreduce is a software framework for easily writing applications which processes vast amounts
of data
Hadoop UseCases
One of the magic of Hadoop is Watson, a supercomputer developed by IBM competed in the popular Question and Answer show Jeopardy!.
- In that contest, Watson was successful in beating the two most winning Jeopardy players.
- Approximately 200 million pages of text were input using Hadoop to distribute the workload for loading this information into memory.
- Once this information was loaded, Watson used other technologies for advanced search and analysis.
In the telecommunication industry we have China Mobile, a company that built a Hadoop cluster to perform data mining on Call Data Records.
- China Mobile was producing 5-8 TB of these records daily.
- By using a Hadoop-based system they were able to process 10x times as much data as when using their old system, and at 1/5 the cost.
In the media, we have the New York Times which wanted to host on their website all public domain articles from 1851 to 1922.
- They converted articles from 11 million image files (4TB) to 1.5TB of PDF documents.
- This was implemented by one employee who ran a job in 24 hours on a 100-instance Amazon EC2 Hadoop cluster at a very low cost.
In the technology field, we again have IBM with IBM ES2, and enterprise search technology based on Hadoop, Nutch, Lucene and Jaql.
- ES2 is designed to address unique challenges of enterprise search such as:
- The Use of enterprise-specific vocabulary abbreviations and acronyms
- ES2 can perform mining tasks to build Acronym libraries, Regular expression patterns, and Geo-classification rules.
There are also many internet or social network companies using Hadoop such as Yahoo, Facebook, Amazon, eBay, Twitter, StumbleUpon, Rackspace, Ning, AOL, etc.
Yahoo, of course, is the largest production user with an application running a Hadoop cluster consisting of about 10,000 Linux machines. Yahoo is also the largest contributor to the Hadoop open source project.
Hadoop Limitations
Hadoop is not a magic bullet that solves all kinds of problems.
- Hadoop is not good to process transactions due to its lack of random access.
- It is not good when the work cannot be parallelized or when there are dependencies within the data, that is, record one must be processed before record two.
- It is not good for low latency data access.
- Not good for processing lots of small files although there is work being done in this area, for example, IBM’s Adaptive MapReduce.
- It is not good for intensive calculations with little data.
Big Data Solutions
Big Data solutions are more than just Hadoop.
- They can integrate analytic solutions to the mix to derive valuable information that can combine structured legacy data with new unstructured data.
- Big data solutions may also be used to derive information from data in motion, for example, IBM has a product called InfoSphere Streams that can be used to quickly determine customer sentiment for a new product based on Facebook or Twitter comments.
Cloud has gained a tremendous track in the past few years, and it is a perfect fit for Big Data solutions. Using the cloud, a Hadoop cluster can be setup in minutes, on demand, and it can run for as long as needed without having to pay for more than what is used.
Hadoop Architecture
There are different terminologies we used in Hadoop;
- Node is simply a computer.
- This is typically non-enterprise, commodity hardware for nodes that contain data.
- So for example, we have Node 1.
- Then we can add more nodes, such as Node 2, Node 3, and so on.
- This would be called a Rack.
- This is typically non-enterprise, commodity hardware for nodes that contain data.
- A Rack is a collection of 30 or 40 nodes that are physically stored close together and are all connected to the same network switch.
- Network bandwidth between any two nodes in the same rack is greater than bandwidth between two nodes on different racks.
A Hadoop Cluster (or just cluster from now on) is a collection of racks.
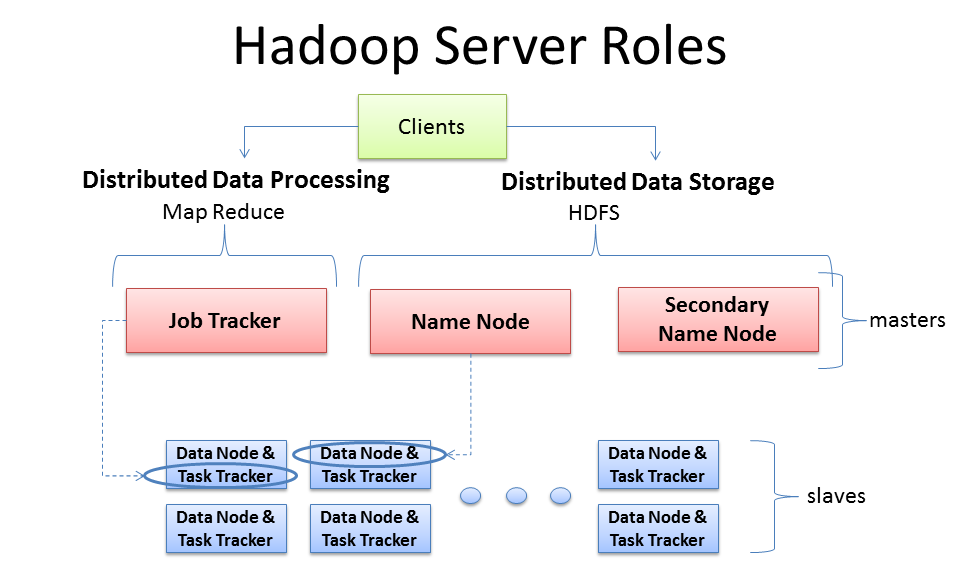
Hadoop Components
Hadoop has two major components:
- HDFS (Hadoop Distributed File System); the distributed filesystem component.
- The main example of which is the HDTS (Hadoop Distributed File System)
- Though other file systems, such as IBM Spectrum Scale.
- The MapReduce Engine; Component, which is a framework for performing calculations on the data in the distributed file system.
- Pre-Hadoop 2.2 MapReduce is referred to as “MapReduce V1” and has its own built-in resource manager and schedule.
Hadoop Distributed File System (HDFS)
HDFS runs on top of the existing file systems on each node in a Hadoop cluster.
- It is not POSIX compliant.
- It is designed to tolerate high component failure rate.
- Reliability is through replication of the data.
Hadoop works best with very large files.
- The larger the file, the less time Hadoop spends seeking for the next data location on disk, the more time Hadoop runs at the limit of the bandwidth of your disks.
- Seeks are generally expensive operations that are useful when they only need to analyze a small subset of your dataset.
- Since Hadoop is designed to run over your entire dataset, it is best to minimize seeks by using large files.
- Hadoop is designed for streaming or sequential data access rather than random access.
- Sequential data access means fewer seeks. since
- Hadoop only seeks to the beginning of each block and begins reading sequentially from there.
- Hadoop uses blocks to store a file or parts of a file.
- HDFS file Blocks
A Hadoop block is a file on the underlying filesystem. Since the underlying filesystem stores files as blocks;
- One Hadoop block may consist of many blocks in the underlying file system.
- Blocks are large. They default to 64 megabytes each and most systems run with block sizes of 128 megabytes or larger.
- Blocks have several advantages:
- Firstly, they are fixed in size. This makes it easy to calculate how many can fit on a disk.
- Secondly, by being made up of blocks that can be spread over multiple nodes, a file can be larger than any single disk in the cluster.
- HDFS blocks also don’t waste space.
- If a file is not an even multiple of the block size, the block containing the remainder does not occupy the space of an entire block. Finally, blocks fit well with replication,
which allows HDFS to be fault tolerant and available on commodity hardware.
- If a file is not an even multiple of the block size, the block containing the remainder does not occupy the space of an entire block. Finally, blocks fit well with replication,
- HDFS Replication
- Each block is replicated to multiple nodes.
- E.g. block 1 is stored on node 1 and node 2. Block 2 is stored on node 1 and node 3. And block 3 is stored on node 2 and node 3.
- This allows for node failure without data loss. If node 1 crashes, node 2 still runs and has block 1’s data.
- * In this example, we are only replicating data across two nodes, but you can set replication to be across many more nodes by changing Hadoop’s configuration or even setting the replication factor for each individual file.
- E.g. block 1 is stored on node 1 and node 2. Block 2 is stored on node 1 and node 3. And block 3 is stored on node 2 and node 3.
- Each block is replicated to multiple nodes.
- MapReduce framework
HDFS was based on a paper Google published about their Google File System,
- Hadoop’s MapReduce is inspired by a paper Google published on the MapReduce technology.
- It is designed to process huge datasets for certain kinds of distributable problems using a large number of nodes.
- A MapReduce program consists of two types of transformations that can be applied to data any number of times
- A map transformation
- A reduce transformation.
- A MapReduce job is an executing MapReduce program that is divided into
- Map tasks that run in parallel with each other.
- Map Reduce tasks that run in parallel with each other.
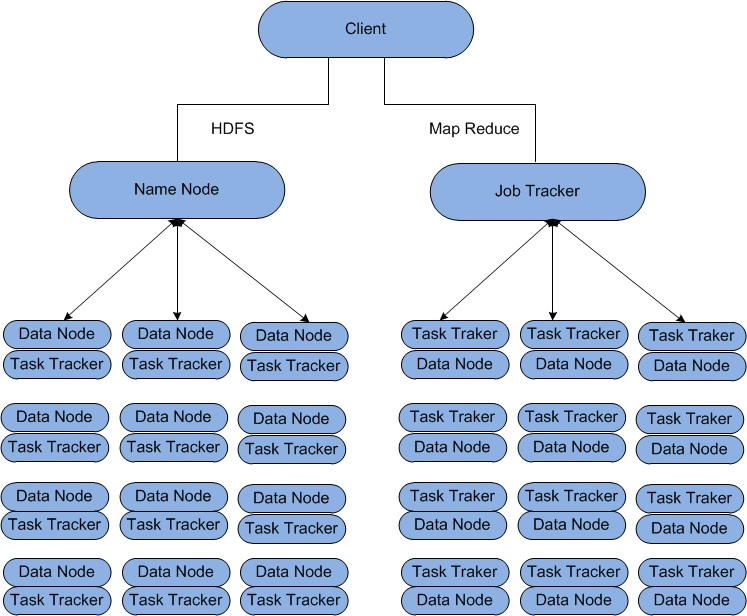
Let us examine the main types of nodes in pre-Hadoop. They are classified as HDFS or MapReduce V1 nodes.
- For HDFS nodes we have the NameNode, and the DataNodes.
- For MapReduce V1 nodes we have the JobTracker and the TaskTracker nodes.
- There are other HDFS nodes such as the Secondary NameNode, Checkpoint node, and Backup node
- A client is shown as communicating with a JobTracker. It can also communicate with the NameNode and with any DataNode.
- There is only one NameNode in the cluster. While the data that makes up a file is stored in blocks at the data nodes, the metadata for a file is stored at the NameNode.
- The NameNode is also responsible for the filesystem namespace.
- To compensate for the fact that there is only one NameNode, one should configure the NameNode to write a copy of its state information to multiple locations, such as a local disk and an NFS mount.
- If there is one node in the cluster to spend money on the best enterprise hardware for maximum reliability, it is the NameNode.
- The NameNode should also have as much RAM as possible because it keeps the entire filesystem metadata in memory.
- The NameNode is also responsible for the filesystem namespace.
Types of Nodes
- DataNodes
A typical HDFS cluster has many DataNodes.
- DataNodes store the blocks of data and blocks from different files can be stored on the same DataNode.
- When a client requests a file, the client finds out from the NameNode which DataNodes stored the blocks that make up that
file and the client directly reads the blocks from the individual DataNodes. - Each DataNode also reports to the NameNode periodically with the list of blocks it stores.
- DataNodes do not require expensive enterprise hardware or replication at the hardware layer.
- The DataNodes are designed to run on commodity hardware and replication is provided at the software layer.
- When a client requests a file, the client finds out from the NameNode which DataNodes stored the blocks that make up that
- JobTracker Nodes
A JobTracker node manages MapReduce V1 jobs. There is only one of these on the cluster.
- It receives jobs submitted by clients.
- It schedules the Map tasks and Reduce tasks on the appropriate TaskTrackers, that is where the data resides, in a rack-aware manner and it monitors for any failing tasks that need to be rescheduled on a different TaskTracker.
- To achieve the parallelism for your map and reduce tasks, there are many TaskTrackers in a Hadoop cluster.
- Each TaskTracker spawns Java Virtual Machines to run your map or reduce task. It communicates with the JobTracker and reads blocks from DataNodes.
Hadoop Architecture
By Hadoop 2.2, it brought about architectural changes to MapReduce. As Hadoop has matured, people have found that it can be used for more than running MapReduce jobs.
But to keep each new framework from having its own resource manager and scheduler, that would compete with the other framework resource managers and schedulers, it was decided to have the resource manager and schedulers to be external to any framework.
YARN
This new architecture is called YARN. (Yet Another Resource Negotiator).
- We still have DataNodes but there are no longer TaskTrackers and the JobTracker.
- We are not required to run YARN with Hadoop 2.2, as MapReduce V1 is still supported.
There are two main ideas with YARN.
- Provide generic scheduling and resource management.
- This way Hadoop can support more than just MapReduce.
- The other is to try to provide a more efficient scheduling and workload management.
With MapReduce V1, the administrator had to define how many map slots and how many reduce slots there were on each node. Since the hardware capabilities for each node in a Hadoop cluster can vary, for performance reasons, you might want to limit the number of tasks on certain nodes. With YARN, this is no longer required.
- With YARN, the resource manager is aware of the capabilities of each node via communication with the NodeManager running on each node. When an application gets invoked , an Application Master gets started.
- The Application Master is then responsible for negotiating resources from the ResourceManager.
- These resources are assigned to Containers on each slave-node and you can think that tasks then run in Containers. With this architecture, you are no longer forced into a one size fits all.
The NameNode is a single point of failure. Is there anything that can be done about that? Hadoop now supports high availability.
In this setup, there are now two NameNodes, one active and one standby.

Also, now there are JournalNodes. There must be at least three and there must be an odd number. Only one of the NameNodes can be active at a time. It is the JournalNodes, workingtogether,, that decide which of the NameNodes is to be the active one and if the active NameNode has been lost and whether the backup NameNode should take over.
Hadoop Federation

The NameNode loads the metadata for the file system into memory. This is the reason that we said that NameNodes needed large amounts of RAM. But you are going to be limited at some point when you use this vertical growth model.
Hadoop Federation allows you to grow your system horizontally.
- This setup also utilizes multiple NameNodes. But they act independently.
- However, they do all share all of the DataNodes.
- Each NameNode has its own namespace and therefore has control over its own set of files.
- For example, one file that has blocks on DataNode 1 and DataNode 2 might be owned by NameNode 1. NameNode 2 might own a file that has blocks on DataNode 2 and DataNode 3. And NameNode 3 might have a file with blocks on all three DataNodes.
Rack Awareness
Hadoop has awareness of the topology of the network. This allows it to optimize where it sends the computations to be applied to the data. Placing the work as close as possible to the data it operates on maximizes the bandwidth available for reading the data.
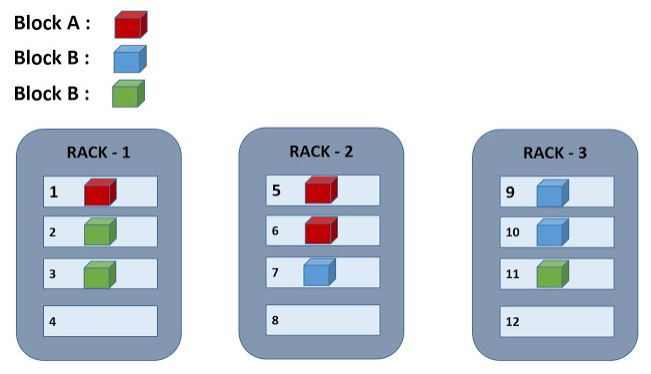
When deciding which TaskTracker should receive a MapTask that reads data from B1, the best option is to choose the TaskTracker that runs on the same node as the data.
- If we can’t place the computation on the same node, our next best option is to place it on a node in the same rack as the data.
- The worst case that Hadoop currently supports is when the computation must be processed from a node in a different rack than the data.
- When rack-awareness is configured for your cluster, Hadoop will always try to run the task on the TaskTracker node with the highest bandwidth access to the data.
HDFS Replication

Let us walk through an example of how a file gets written to HDFS.
- First, the client submits a “create” request to the NameNode.
- The NameNode checks that the file does not already exist and the client has permission to write the file.
- If that succeeds, the NameNode determines the DataNode to where the first block is to be written.
- If the client is running on a DataNode, it will try to place it there.
- Otherwise, it chooses DataNode at random. By default, data is replicated to two other places in the cluster.
- A pipeline is built between the three DataNodes that make up the pipeline.
- The second DataNode is a randomly chosen node on a rack other than that of the first replica of the block. This is to increase edundancy.
- The final replica is placed on a random node within the same rack as the second replica.
- The data is piped from the second DataNode to the third.
- To ensure the write was successful before continuing, acknowledgment packets are sent from the third DataNode to the second, From the second DataNode to the first And from the first DataNode to the client This process occurs for each of the blocks that makes up the file Notice that, for every block, by default, there is a replica on at least two racks.
- When the client is done writing to the DataNode pipeline and has received acknowledgments, it tells the NameNode that the write has completed.
- The NameNode then checks that the blocks are at least minimally replicated before responding.

