Motivation
Big data is an amount of data that you cannot deal with using traditional methods and it’s very relative because big data five years ago is not big data today so it’s constantly evolving. I think it’s when you have a great amount of data. Not only can you not store it, but you can’t process this data with your home computers. : – )
What is Big Data?
Well, there is no one specific definition, we may define Big Data in different ways.
Big data is any amount of data that can’t fit in memory. It’s an evolving definition that changes with the times. Whenever our dataset extends beyond the capacity of our systems to store and manipulate, it’s big data.
It means that if you have a laptop and your data doesn’t fit on your laptop, that’s big data for you. : – )
But if you are a very large firm and you’ve got large clusters of storage space and even then your data exceeds the storage capacity of your systems, then that’s big data for you; so big data is not something that you can say, well, 50 gigabytes or 50 petabytes would make it big data,
it is whenever a person, individual or firm’s storage capacity or the ability to analyze data is exceeded by the amount of data that they have,
that becomes big data for them.
We can play with big data. If we have a lot of data we can do visualization and analytics. We are generating more knowledge nowadays
and this is difficult for humans to get used to it. That’s remarkable; really, really remarkable.
Data science is relevant today because we have tons of data available. We used to worry about lack of data, now we have a data deluge. In the past, we didn’t have algorithms, now we have algorithms. In the past the software was expensive, now it’s open source and it’s free. In the past we couldn’t store large amounts of data, now for a fraction of a cost, we can have gazillions of data sets for a very low cost. So the tools to work with data, the very availability of data and the ability to store and analyze data, it’s all cheap, it’s all available, it’s all ubiquitous, it’s here, there’s never been a better time to be a data scientist. : – )

So lets further define Big Data and familiar with the characteristics of Big Data.
- Big Data is the digital trace that we are generating in this digital era. This digital trace is made up of all the data that is captured when we use digital technology. The basic idea behind the phrase Big Data is that everything we do is increasingly leaving a digital trace which we can use and analyze to become smarter. The driving forces in this brave new world are access to ever-increasing volumes of data and our ever-increasing technological capability to mine that data for commercial insights.
- Big Data is high-volume, high-velocity, and/or high variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making and process automation.
- Big Data refers to the dynamic, large and disparate volumes of data being created by people, tools, and machines. It requires new, innovative, and scalable technology to collect, host and analytically processes the vast amount of data gathered in order to derive real-time business insights that relate to consumers, risk, profit, performance, productivity management, and enhanced shareholder value.
- Big Data as a collection of data from traditional and digital sources inside and outside a company that represents a source of ongoing discovery and analysis.
Vs of Big Data
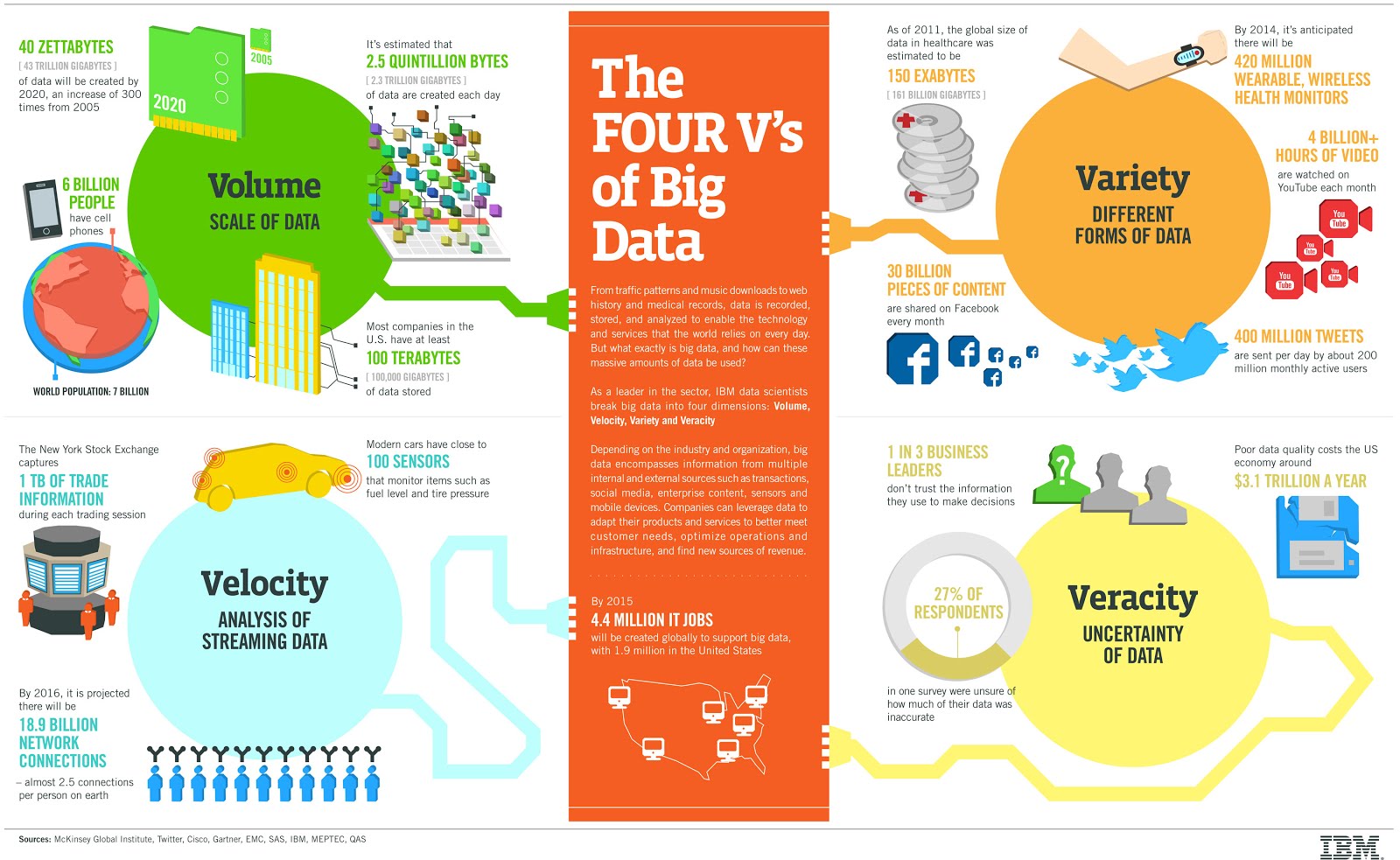
Well, as there is no one definition of Big Data, but there are certain elements that are common across different definitions, such as velocity, volume, variety, and veracity. These are the V’s of Big Data.
- Velocity is the speed of the data or the speed at which data accumulates.
- Velocity is the idea that data is being generated extremely fast, a process that never stops. Attributes include near or real-time streaming and local and cloud-based technologies that can process information very quickly.
- E.g. Every 60 seconds, hours of footage are uploaded to YouTube.
- This amount of data is generated every minute. So think about how much accumulates over hours, days, and in years.
- E.g. Every 60 seconds, hours of footage are uploaded to YouTube.
- Velocity is the idea that data is being generated extremely fast, a process that never stops. Attributes include near or real-time streaming and local and cloud-based technologies that can process information very quickly.
- Volume is the scale of the data or the increase in the amount of data stored.
- Volume is the amount of data generated. For example, exabytes, zettabytes, yottabytes, etc… Drivers of the volume are the increase in data sources, higher resolution sensors and scalable infrastructure.
- E.g. Every day we create approximately 2.5 quintillion bytes of data. That’s 10 million Blu-ray DVD’s every day. The world population is approximately seven billion people, and the vast majority of people are now using digital devices. These devices all generate, capture, and store data.
And with more than one device, for example, mobile devices, desktop computers, laptops, et cetera,
we’re seeing even more data being produced.
- E.g. Every day we create approximately 2.5 quintillion bytes of data. That’s 10 million Blu-ray DVD’s every day. The world population is approximately seven billion people, and the vast majority of people are now using digital devices. These devices all generate, capture, and store data.
- Volume is the amount of data generated. For example, exabytes, zettabytes, yottabytes, etc… Drivers of the volume are the increase in data sources, higher resolution sensors and scalable infrastructure.
- Variety is the diversity of the data. We have structured data that fits neatly into rows and columns, or relational databases and unstructured data that is not organized in a pre-defined way, for example, Tweets, blog posts, pictures, numbers, and even video data.
- Veracity is the quality and origin of data. Attributes include consistency, completeness, integrity, and ambiguity. Drivers include cost and the need for traceability.
- E.g. Let’s think about the different types of data, text, pictures, and film. What about sound, health data from wearable devices, and many different types of data from devices connected to the internet of things.
- Veracity is the quality and origin of data. Attributes include consistency, completeness, integrity, and ambiguity. Drivers include cost and the need for traceability.
- Veracity is the conformity to facts and accuracy. With a large amount of data available, the debate rages on about the accuracy of data in the digital era. Is the information real, or is it false?
- Variety is the idea that data comes from different sources, machines, people, processes, both internal and external to organizations. Attributes include the degree of structure and complexity and drivers are mobile technologies, social media, wearable technologies, geo-technologies, video, and many, many more.
- E.g. 80% of data is considered to be unstructured and we must devise ways to produce reliable and accurate insights. The data must be categorized, analyzed and visualized.
- Variety is the idea that data comes from different sources, machines, people, processes, both internal and external to organizations. Attributes include the degree of structure and complexity and drivers are mobile technologies, social media, wearable technologies, geo-technologies, video, and many, many more.
- And the last and emerging V is Value.
- This V refers to our ability and needs to turn data into value.
- Value isn’t just profit. It may be medical or social benefits, or customer, employee, or personal satisfaction. The main reasons why people invest time to understand Big Data is to derive value from it.
- This V refers to our ability and needs to turn data into value.
Big Data in Bussiness
Many of us are generating and using big data without being aware that we are. How is big data impacting business and people?
If we searched for or bought a product on Amazon or famous e-commerce platform. We can notice that we start getting recommendations related to the product we searched for. So that recommendation engines are a common application of big data.
Companies like Amazon, Netflix and Spotify use algorithms based on big data to make specific recommendations based on customer preferences and historical behavior.
Personal assistants like Siri on Apple devices use big data to devise answers to the infinite number of questions end users may ask. Google now makes recommendations based on the big data on a user’s device.
Let’s take a look at how big data is impacting business.
- In 2011, McKinsey & Company said that big data was going to become the key basis of competition
supporting new waves of productivity growth and innovation. - In 2013, UPS announced that it was using data from customers, drivers, and vehicles in a new route guidance system aimed to save time, money and fuel.
Initiatives like this one support the statement that big data will fundamentally change the way businesses compete and operate.
- Netflix has a lot of data. Netflix knows the time of day when movies are watched. It logs when users pause, rewind and fast forward.
It has ratings from millions of users as well as the information on searches they make.
By looking at all these big data, Netflix knew what many of its users had streamed. All these information suggested that buying the series would be a good bet for the company.- In other words, thanks to big data, Netflix knows what people want before they do.
Now let’s review another example.
- Market saturation and selective customers will require Chinese e-commerce companies to make better use of big data in order to gain market share.
- Companies will have to persuade customers to shop more frequently, to make larger purchases and to buy from a broader array of online shopping categories.
- E-commerce players already have the tools to do this as digital shopping grows. Leading players are already using data to build models aimed at boosting retention rates and spending per customer based on e-commerce data.
- They have also started to adopt analytics backed pricing and promotional activities. The Internet of Things refers to the exponential rise of connected devices.

IoT suggests that many different types of data today products will be connected to a network or to the internet for example refrigerators, coffee machines or pillows. Another connection of IoT is called wearables and it refers to items of clothing or things we wear that are now connected. These items include Fitbits, Apple Watches or the new Nike running shoes that tie their own shoelaces.
Sources and Types of Big Data
Well, why is everyone talking about Big Data?
More data has been created in the past two years than in the entire history of humankind. By 2020, about 1.7 megabytes of new information will be created every second for every human being in the world.
By 2020, the data we create and copy will reach around 35 zettabytes, up from only 7.9 zettabytes today. Note the jump from 2015 to 2020 of 343%.
- * How big is a Zettabyte?
- One Terabyte is 1025 Gigabytes.
- 1024 Terabytes make up one Petabyte,
- And 1024 Petabytes make up an Exabyte.
Think of a big urban city or a busy international airport And now we’re talking petabytes and exabytes.
- All those airplanes are capturing and transmitting data.
- All the people in those airports have mobile devices.
- Also, consider the security cameras and all the staff in and around the airport.
A digital universe study conducted by IDC claimed;
- Digital information reached 0.8 zettabytes last year and predicted this number would grow to 35 zettabytes by 2020.
It is predicted that;
- By 2020, one-tenth of the world’s data will be produced by machines, and most of the world’s data will be produced in emerging markets.
It is also predicted that;
- The amount of data produced will increasingly outpace available storage.
Advances in cloud computing have contributed to the increasing potential of Big Data.
Cloud computing allows users to access highly scalable computing and storage resources through the internet. By using cloud computing, companies can use server capacity as needed and expand it rapidly to the large scale required to process big data sets and run complicated mathematical models.
Cloud computing lowers the price to analyze big data as the resources are shared across many users, who pay only for the capacity they actually utilize.
A survey by IBM and SAID Business School identified three major sources of Big Data.
- People-generated data
- Machine-generated data
- Business-generated data
Which is the data that organizations generate within their own operations.
Big Data will require analysts to have Big Data skills. Big Data skills include discovering and analyzing trends that occur in Big Data.
Big Data comes in three forms.
- Structured
- Structured data is data that is organized, labeled, and has a strict model that it follows.
- Some sources of structured Big Data are relational databases and spreadsheets.
- With this type of structure, we know how data is related to other data.
- What the data means, and the data is easy to query, using a programming language like SQL.
- Structured data refers to any data that resides in a fixed field within a record or file. It has the advantage of being easily entered, stored, queried, and analyzed.
- In today’s business setting, most Big Data generated by organizations is structured and stored in data warehouses. Highly structured business-generated data is considered a valuable source of information and thus equally important as machine and people-generated data.
- Structured data is data that is organized, labeled, and has a strict model that it follows.
- Unstructured
- Unstructured data is said to make up about 80% of data in the world, where the data is usually in a text form and does not have a predefined model or is organized in any way.
- Semi-structured
- Semi-structured data is a combination of the two. It is similar to structured data, where it may have an organized structure, but lacks a strictly-defined model.
- Some sources of semi-structured Big Data are XML and JSON files. These sources use tags or other markers to enforce hierarchies of records and fields within data.
- Semi-structured data is a combination of the two. It is similar to structured data, where it may have an organized structure, but lacks a strictly-defined model.
A large multi-radio telescope project called Square Kilometer Array, or SKA, produced about 1000 petabytes, in 2011 at least, of raw data a day.
- It is projected that it will produce about 20,000 petabytes or 20 billion gigabytes of data each day in 2020.
- Currently, there is an explosion of data coming from internet activity and in particular, video production and consumption as well as social media activities.
These numbers will just keep growing as internet speeds increase and as more and more people all over the world have access to the internet.
Big Data relates to Data Science;
When we look at big data, we can start with a few broad topics, the 6 aspects:
- Integration
- To integrate means to bring together or incorporate parts into a whole.
- In big data, it would be ideal to have one platform to manage all of the data, rather than individual silos, each creating separate silos of insight.
- Big data has to be bigger than just one technology or one enterprise solution which was built for one purpose.
- For example, a bank should be thinking about how to integrate its retail banking, it’s commercial banking, and investment banking.
- One way to be bigger than one technology is to use Hadoop when dealing with big data. A Hadoop distributed file system, or HDFS, stores data for many different locations, creating a centralized place to store and process the data.
- For example, a bank should be thinking about how to integrate its retail banking, it’s commercial banking, and investment banking.
- To integrate means to bring together or incorporate parts into a whole.
- Analysis
- Let’s look at a Walmart example.
- Walmart utilizes a search engine called Polaris,
- That helps shoppers search for products they wish to buy.
- It takes into account how a user is behaving on the website in order to surface the best results for them.
- Polaris will bring up items that are based on a user’s interests and because many consumers visit Walmart’s website, large amounts of data are collected, making the analysis on that big data very important.
- Walmart utilizes a search engine called Polaris,
- Let’s look at a Walmart example.
- Visualization and Optimization
- Some people work well with tables of data, however, the vast majority of people need big data to be presented to them in a graphical way so they can understand it.
- Data visualization is helpful to people who need to analyze the data, like analysts or data scientists, and it is especially useful to non-technical people who need to make decisions from data, but don’t work with it on a daily basis.
- An example of visualizing big data is in displaying the temperature on a map by region.
- By using the massive amounts of data collected by sensors and satellites in space, viewers can get a quick and easy summary of where it’s going to be hot or cold.
- Security and Governance
- Data privacy is a critical part of the big data era. Business and individuals must give great thought to how data is collected, retained, used, and disclosed. A privacy breach occurs when there is unauthorized access to or collection, use, or disclosure of personal information and, often, this leads to litigation.
- Companies must establish strict controls and privacy policies in compliance with the legal framework of the geographic region they are in.
- * Big data governance requires three things:
- Automated integration, that is, easy access to the data wherever it resides,
- Visual content, that is, easy categorization, indexing, and discovery within big data to optimize its usage,
- Agile governance is the definition and execution of governance appropriate to the value of the data and its intended use.
Looking at these three things provides businesses with a quick way to profile the level of importance of the data and, therefore, the amount of security required to protect it.
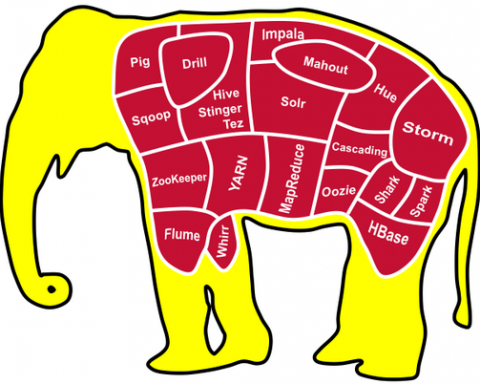
Big Data Tools
Some of the applications used in big data are;
- Hadoop
- Oozie
- Flume
- Hive
- HBase
- Apache Pig
- Apache Spark
- MapReduce and YARN
- Sqoop
- ZooKeeper
- Text analytics.
Data science is the process of cleaning, mining, and analyzing data to derive insights of value from it.
- In data science, the size of the data is less important.
- One can use data of all sizes, small, medium, and big data that is related to a business or scientific case.
- Insights are extracted through a combination of exploratory data analysis and modeling.
Data science is the process of distilling insights from data to inform decisions.
Data Scientist Skills;
A data scientist is a person who is qualified to derive insights from data by using skills and experience from computer science, business, or science, and statistics.

Here are more skills that a data scientist must have. One can use the following process to make sense of big data.
- Determine the problem.
- What is the business problem?
- What is the project objective?
- What would you do if you had all the data?
- Collect data.
- Which data is relevant?
- Are there any privacy issues?
- Explore the data.
- Plot the data.
- Are there any patterns?
- Analyze the data.
- Build a model.
- Fit the model.
- Validate the model.
- Storytelling.
- Visualization plus communication.
- Can we tell a story?
- Take action and make decisions.
Processing Big Data;
Component and Ecosystem of Big Data;
In a report by the McKinsey Global Institute from 2011, the main components and ecosystems are out outlined as follows: Techniques for Analyzing Data, such as A/B Testing, Machine Learning, and Natural Language Processing.
Big Data Technologies like Business Intelligence, Cloud Computing, and Databases. Visualization such as Charts, Graphs, and Other Displays of the data.
The Big Data processing technologies we will discuss work to bring large sets of structured and un-structured data into a format where analysis and visualization can be conducted.
Value can only be derived from Big Data if it can be reduced or repackaged into formats that can be understood by people.
One trend making the Big Data revolution possible is the development of new software tools and database systems such as Hadoop, HBase, and NoSQL for large, unstructured data sets. what is the Hadoop framework?
Hadoop is an open-source software framework used to store and process huge amounts of data. It is implemented in several distinct, specialized modules:
- Storage, principally employing the Hadoop Distributed File System or HDFS
- Resource management and scheduling for computational tasks,
- Distributed processing programming models based on MapReduce,
- Common utilities and software libraries necessary for the entire Hadoop platform.
Hadoop is a framework written in Java, originally developed by Doug Cutting who named it after his son’s toy elephant.
Hadoop uses Google’s MapReduce technology as its foundation. Let’s review some of the terminology used in any Hadoop discussion.
- A Node is simply a computer. This is typically non-enterprise, commodity hardware that contains data. So in this example, we have node one, then we can add more nodes such as node two, node three, and so on.
- This would be called a Rack;
- A rack is a collection of 30 or 40 nodes that are physically stored close together and are all connected to the same network switch.
- Network bandwidth between any two nodes in a rack is greater than bandwidth between two nodes on different racks.
- The Hadoop Cluster is a collection of racks.
- IBM analytics defines Hadoop as follows, “Apache Hadoop is a highly scalable storage platform designed to process very large data sets across hundreds to thousands of computing nodes that operate in parallel.
- It provides a cost-effective storage solution for large data volumes with no format requirements.
- MapReduce, the programming paradigm that allows for this massive scalability, is the heart of Hadoop.”
Why Hadoop?
According to IBM analytics, some companies are delaying data opportunities because of organizational constraints. Others are not sure what distribution to choose and still others simply can’t find time to mature their Big Data delivery due to the pressure of day to day business needs.
The smartest Hadoop strategies start with choosing recommended distributions, then maturing the environment with modernized hybrid architectures, and adopting a data lake strategy based on Hadoop technology.
- Data lakes are a method of storing data that keep vast amounts of raw data in their native format and more horizontally to support the analysis of originally disparate sources of data.
- Big Data is best thought of as a platform rather than a specific set of software. Data Warehouses are part of a Big Data platform.
- They deliver deep insight with advanced in-database analytics and operational analytics.
Data Warehouses provide online analytic processing or OLAP.
- Data Warehouse Modernization, formerly known as Data Warehouse Augmentation, is about building
on an existing Data Warehouse infrastructure leveraging Big Data technologies to augment its capabilities, essentially an upgrade.
Given a set of data, there are three key types to Data Warehouse Modernizations.
- Pre-Processing, using Big Data as a landing zone before determining what data should be moved to the Data Warehouse.
- It could be categorized as Irrelevant Data and Relevant Data, which would go to the Data Warehouse.
- Offloading, moving infrequently accessed data from Data Warehouses into enterprise grade Hadoop.
- Exploration, using big data capabilities to explore and discover new high value data from massive amounts of raw data and free up the Data Warehouse for more structured deep analytics.
Conclusion
So that can be a quick overview of Big Data and its tools along with skills used nowadays. One can have a good understanding of Bid Data after the quick review of this blog. Further, you can have a quick look at the Big Data implementation at Microsoft Platform here; http://justsajid.com/dev/jumpstart-into-big-data-with-hdinsight/
* The Blog post was tribute the big data course available at Cognitive class. It is highly recommended to review the course from here; https://cognitiveclass.ai/courses/what-is-big-data/