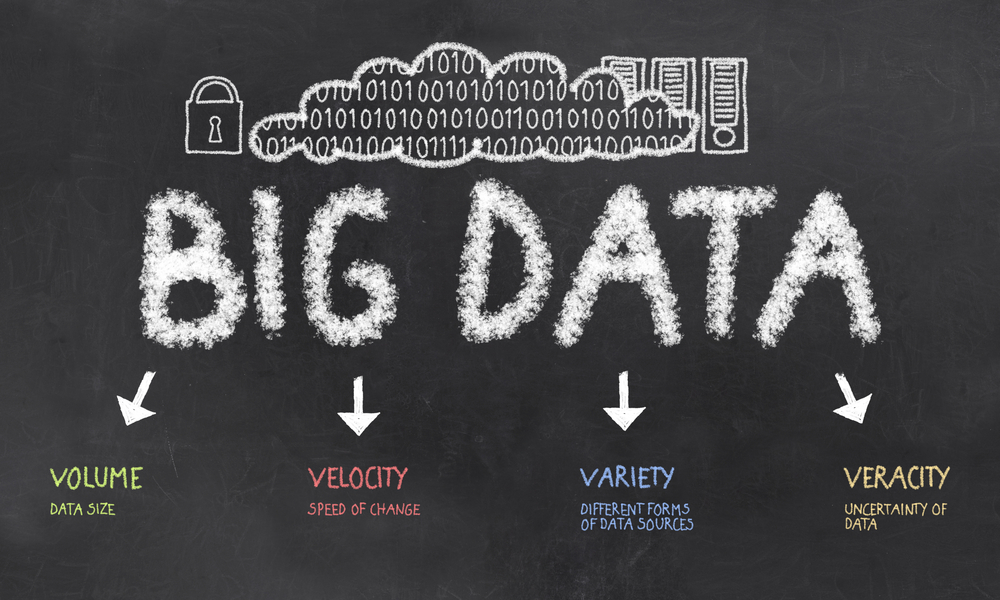
What would happen when the volume of your data increased repeatedly over time and you need high velocity at the same time. Not only that but you have a different variety of data and Variability also exists in your data. So how would you handle all that data?
If we particularly talk about an existing example, NASA is going to launch a Telescope very soon that would generate a huge amount of data in 1 sec which would be more than the data generated by Google in a year. So from that, we can predict the complexity of data which would come in the near future,
So, the biggest question arises here is who and how would we able to handle that huge amount of data. Do we need the infinite number of machines who can handle all of that data? But, as we all know that machines are quite limited and we also do not put supercomputers everywhere. So what we would do?
But wait! Here comes the concept of Big Data.
So, what exactly Big Data is. Big Data is the solution for that huge amount of data under limited resources.
According to the experts, the third generation web will rotate around Big Data. And as we all know Moore’s Law, that can also be applied to Computing Data but in the case of data, it’s not the double but an increased number of times. So Big Data provides the solution that handles high volume data under limited resources.
Moreover, we need high velocity to process that large amount of data. If we talk about the normal computing machine, it takes a lot of time to process data even in GBs. But in Big Data, we are talking about Zettabyte (ZB) and Yottabyte (YB) and we also want to process that huge data in a very limited time to get results in time. So, don’t worry! Big Data provides that solution and handle that huge amount of data in high velocity.
Further, as we all know that data exist in a large variety. In that we take the simplest example then we have Facebook and Twitter at the front of us where we people own different types of data. And we also know that billions of users exist in those huge social network sites (SNS). So how SNSs would handle the different variety of data in the meantime when they have a large number of users processing data at the same time. So, again Big Data provides that solution to handle the different variety of data in huge quantities.
As we see variability in data. So when we talk about Inconsistency which can be shown by the data at times at high level, how would we handle that data. So again it’s the Big Data that provides the solution that handles the variability of data at the big level.
But wait! The Big Data solution provides by different organizations. The best solution is found from Microsoft. Microsoft Provides Big Data solution through Microsoft Azure HDInsight!
Data is there forever and there had been awesome technologies build by Microsoft also by its competitors. Hadoop is an Open Source, Scalable, Fault Tolerant Platform for the large amount of unstructured data storage and processing, distributed across a large number of machines.
Here the scale is big, so the challenges are really really entrusting that is why Big Data and whole new set of technologies have come. So we are primarily going to talk about Hadoop. Again, Big data is a huge topic. It cannot be defined simply. So for better understanding we are defining it simply.
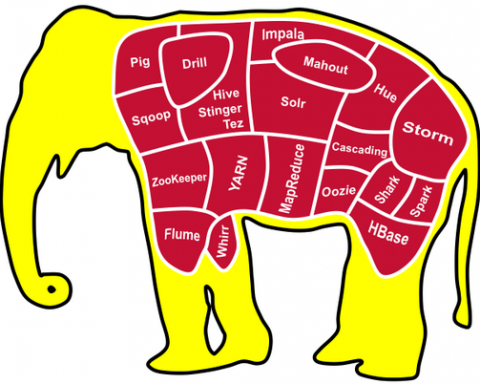
There are three things. ‘Batch’, ‘NoSQL Store’ and a streaming solution ‘Storm’ and some others. So these are all technologies that come under the umbrella of HDInsight that is Big Data service on Azure.
Microsoft cloud Big Data offering 100% open source Apache Hadoop Up and running in minutes with no hardware to deploy Harness existing .NET skills utilize familiar BI tools and application frameworks.
So as described above HDInsight is Azure Big Data offering, what they do is, they take the open source which is Hadoop. Microsoft like other enterprise competitors goes back in the main trunk so everyone else can take benefit. In Microsoft, it is fully managed. No Worries!
In other technologies, people have to set their Clusters manually, which is so hard. So, the first thing we can do is, we just go in Azure and say I want H-base, I want Hadoop and I want a five hundred node cluster. In just 15 minutes we’ll have every set up for us by Microsoft Azure. It is a fully managed service.
So there are few things, first, one is HIVE. The HIVE is a powerful query language. In the traditional way, we define the schema first and then we write it. But, in Big Data world, first, we write the scheme and then we define it. So that is changed the way we handle the data. Here we don’t need to worry about the data. How will the relationship will be defined? So all we do is, storing the data. And whenever we need to do something we define the table and start writing our queries.
The second one is HBase that is a NoSQL store. It gives us a really fast read and writes access. Like Facebook messaging it build on HBase. Skype also do their lot of stuff in HBase. Now you can understand the power of that where we can go, store our data and then build our apps on top of it.
The last one is Storm, it is used for Streaming. Here we have a thing ‘Topology’ that is made of ‘Spouts’ and ‘Bolts’. We just write a Spout which is a connector. After that, we go and connect to a source or Node. And when we do our business operations, and those are the Bolts, the Storm is the pipeline, that is how the data is flowing and when we do multiple operations in there.
Long story short; Big Data has the capability to query through HIVE. It has NoSQL store which is HBase. It has the streaming pipeline which is called the Storm and in there we build the Topology which is made of Spouts and Bolts.
Well, the story of Big Data is very big. I have just written small things from it. From that one can develop any type of App; that can give the live stream of data anywhere.
Here is an app that is a perfect example of Big Data,
So, HDInsight is one of the greatest services through Microsoft Azure for Big Data Solutions provided by Microsoft. Technically that is used to deploy and provision Hadoop clusters in the Azure cloud, providing a software framework designed to manage, analyze and report on big data.
It makes the different software framework and related projects such as HDFS/MapReduce Pig, Sqoop, and Hive available in a simpler, more scalable, and cost-efficient environment.
In conjunction with the general availability of Azure HDInsight, Microsoft also provides HDInsight Emulator for Azure. The Emulator targets developer scenarios and only supports single-node deployments.
HDInsight uses the Hortonworks Data Platform (HDP) Hadoop distribution. Hadoop often refers to the entire Hadoop ecosystem of components, which includes Storm and HBase clusters, as well as other technologies under the Hadoop umbrella.
Let’s do some hands-on HDInsight.
Let’s assume, you have a large unstructured data set and you want to run a Hive query on it to extract some meaningful information.
So, let’s start by provisioning a Hadoop cluster. When you provision a cluster, you provision Azure compute resources that contain Hadoop and related applications.In order to provision a Hadoop cluster simply Sign in to your Azure Portal,

Now click NEW, then click Data + Analytics, and click HDInsight;
.png)
Now enter a Cluster Name, select Hadoop for the Cluster Type, and from the Cluster Operating System drop-down, select Windows. If you have more than one subscription, click the Subscription entry to select the Azure subscription that will be used for the cluster:
.png)
In Cluster Credentials, simply give smart credentials. If you want to enable remote desktop on the cluster node, for Enable Remote Desktop, click Yes, and then specify the required values. After that hit Select:
.png)
Now in Data Source, choose an existing data source for the cluster, or create a new one. Basically, when you provision a Hadoop cluster in HDInsight, you specify an Azure Storage account. A specific Blob storage container from that account is designated as the default file system, like in the Hadoop Distributed File System (HDFS). By default, the HDInsight cluster is provisioned in the same data center as the storage account you specify:
.png)
From the above Blade, you can realize that currently you can select an Azure Storage Account as the data source for an HDInsight cluster. Use the following to understand the entries on the Data Source blade.
Now, click ‘Node Pricing Tiers’ to display information about the nodes that will be created for this cluster. Set the number of worker nodes that you need for the cluster. The estimated cost of the cluster will be shown within the blade:
.png)
You may change the Pricing Tiers according to your needs and demands.Now simply click to Create the Cluster. You will see that the magic will happen and Azure will start creating Cluster for you. While provisioning the Cluster you’ll see the image like here on your Azure Home Screen:
.png)
While the Provisioning will complete, you will see the following image:
.png)
So by playing with a few clicks, you’ve easily created Cluster. If you ever did that manually that must realize the importance and value of Microsoft Azure.It will take a few minutes to complete. Once the provisioning completes, click the title for the cluster from the Starboard to launch the cluster blade.A successfully provisioned HDInsight cluster provides a query console that includes a Getting Started gallery to run samples directly from the portal.You can use the samples to learn how to work with HDInsight by walking through some basic scenarios. These samples come with all the required components, such as the data to analyze and the queries to run on the data. To learn more about the samples in the Getting Started gallery, see Learn Hadoop in HDInsight using the HDInsight Getting Started Gallery.So! In order to run the sample. Simply go to Dashboard. When prompted, enter the credentials for the cluster:
.png)
So, a new page will open:
.png)
Now, after clicking the Getting Started Gallery tab, under the “Solutions With Sample Data” category, click the sample that you want to run…Follow the instructions on the Web page to finish the sample. The following lists a couple of samples and provides more information about what each sample does:
- Sensor Data Analysis – Learn how to use HDInsight to process historical data that is produced by heating, ventilation, and air conditioning (HVAC) systems to identify systems that are not able to reliably maintain a set temperature.
- Website Log Analysis- Learn how to use HDInsight to analyze website log files to get insight into the frequency of visits to the website in a day from external websites, and a summary of website errors that the users experience.
- Twitter Trend Analysis – Learn how to use HDInsight to analyze trends in Twitter.
Now to run a Hive Query and simply click the ‘Hive Editor’ tab:
.png)
There are several tabs at the top of the page. The default tab is Hive Editor, and the other tabs are Job History and File Browser. By using the dashboard, you can submit Hive queries, check Hadoop job logs, and browse files in storage.
Now on the Hive Editor tab, for Query Name, enter H20. The query name is the job title. In the query pane, enter the Hive query as shown in the image:
.png)
Now simply click Submit. It takes a few moments to get the results back. The screen refreshes every 30 seconds. You can also click Refresh to refresh the screen:
.png)
Now, after the status shows that the job is completed, click the query name on the screen to see the output. Make a note of Job Start Time (UTC) since you will need it later. The page also shows the Job Output and the Job Log. You also have the option to download the output file (_stdout) and the log file (_stderr):
.png)
Now, in order to browse to the output file.; Simply go to the On the cluster dashboard, click File Browser:
.png)
Now click your storage account name, click your container name (which is the same as your cluster name), and then click user. After that lick admin and then click the GUID that has the last modified time (a little after the job start time you noted earlier). Copy this GUID. You will need it in the next section:
.png)
Further you can use the Power Query add-in for Microsoft Excel to import the job output from HDInsight into Excel, where Microsoft business intelligence tools can be used to further analyze the results:
- Download Microsoft Power Query for Microsoft Excel from the Microsoft Download Center and install it.
.png)
So, in order to import HDInsight data, simply Open Excel, and create a new workbook:
.png)
Now simply enter the Account Name and Access Key of the Azure Blob Storage account that is associated with your cluster, and then click OK.
.png)
Now simply in the right pane, double-click the blob name. By default, the blob name is the same as the cluster name.
.png)
Now in a while data will be loaded in Excel Sheet. Locate “stdout” in the Name column. Verify that the GUID in the corresponding Folder Path column matches the GUID you copied earlier. A match suggests that the output data corresponds to the job you submitted. Click Binary in the column left of ‘stdout’.
.png)
You see, how easily by following few steps and clicks we have provision a Hadoop cluster on Windows in HDInsight, run a Hive query on data, and import the results into Excel, where they can be further processed and graphically displayed with BI tools.
Now, let’s play with HDInsight Tools for Visual Studio to connect to HDInsight clusters and submit Hive queries…
Simply install HDInsight tools for Visual Studio. But don’t worry HDInsight Tools for Visual Studio and Microsoft Hive ODBC Driver are packaged with Microsoft Azure SDK for .NET.Now simply open Visual Studio, Open Server Explorer Window, Expand Azure (Also Give Your Azure Credentials if it asks) and then expand HDInsight. In Server Explorer, you’ll see a list of existing HDInsight clusters.
.png)
You can see the HDInsight cluster, Hive Databases, a default storage account, linked storage accounts, and Hadoop Service log. You can further expand the entities.
.png)
Now Simply navigate the linked resources. If you expand the default storage account, you can see the containers on the storage account. The default storage account and the default container are marked. You can also right-click any of the containers to view the contents:
.png)
Now let’s run a Hive Query. Basically, Hive is a data warehouse infrastructure built on Hadoop for providing data summarization, queries, and analysis. And HDInsight Tools for Visual Studio supports running Hive queries from Visual Studio.
It is time consuming to test Hive script against an HDInsight cluster. It could take several minutes or more. HDInsight Tools for Visual Studio is capable of validating Hive script locally without connecting to a live cluster.
HDInsight Tools for Visual Studio also enables users to see what’s inside the Hive job by collecting and surfacing the YARN logs of certain Hive jobs.Let’s see the Hive Sample Data. Actually all HDInsight clusters come with a sample Hive table called hivesampletable. We’ll use this table to show how to list Hive tables, view the table schemas, and list the rows in the Hive table:
.png)
Simply right-click hivesampletable, and then click View Top 100 Rows to list the rows. It is equivalent to running the following Hive query using Hive ODBC driver: SELECT * FROM hivesampletable LIMIT 100.
.png)
Further you can customize the row count:
.png)
Now let’s create Hive tables. Like before, you can use either the GUI to create a Hive table or use Hive queries.
In the Server Explorer, simply go to Hive Databases, then right-click default, and click Create Table;
.png)
And simply configure the table and click Create Table to submit the job to create the new Hive table:
.png)
So, in order to Validate and run Hive queries, there are two ways to create and run Hive queries:
- Create ad-hoc queries
- Create a Hive application
- Create Ad-Hoc queries:
- Simply right-click the cluster where you want to run the query, and then click Write a Hive Query.
- Enter the Hive queries. Notice the Hive editor also supports IntelliSense. HDInsight Tools for Visual Studio supports loading the remote metadata when you are editing your Hive script. For example, when you type “SELECT * FROM”, the IntelliSense lists all the suggested table names. When a table name is specified, the column names are listed by the IntelliSense. The tool supports almost all Hive DML statements, subqueries, and the built-in UDFs.
.png)
.png)
Perhaps only the metadata of the clusters that is selected in HDInsight Toolbar will be suggested.
- (Optional): Click Validate Script to check the script syntax errors,
.png)
Click Submit or Submit (Advanced). With the advanced submit option, you’ll configure Job Name, Arguments, Additional Configurations, and Status Directory for the script:
.png)
After you submit the job, you see a Hive Job Summary window,
.png)
- Use the Refresh button to update the status until the job status changes to completed. Simply click the links at the bottom to see the following: Job Query, Job Output, Job log, or Yarn log.
- Create a Hive application:
Now simply create a Hive Application Project in Visual Studio by selecting HDInsight in Project Templates:
.png)
And in Script.hql simply add queries and then to validate the Hive script, you can click the Validate Script button, or right-click the script in the Hive editor, and then click Validate Script from the context menu:
.png)
See, how simple was that.
Now let’s View Hive jobs. You can view job queries, job output, job logs, and Yarn logs for Hive jobs.
The most recent release of the tool allows you to see what’s inside your Hive jobs by collecting and surfacing YARN logs. A YARN log can help you investigating performance issues.
So, to view Hive jobs simply right-click on HDInsight cluster, and then click View Jobs. You’ll see a list of the Hive jobs that ran on the cluster.
.png)
Now click a job in the job list to select it, and then use the Hive Job Summary window to open Job Query, Job Output, Job Log, or Yarn log:
.png)
Further there are a lot of other features Visual Studio Tools provide for Hive Query.
You can see how simple it was to play with HDInsight. But behind this all magic its Microsoft Azure which control everything and user can perform their task in just few clicks. And for the Big Data solution, HDInsight is the perfect solution by Microsoft.
To get more hands-on experience with HDInsight Solution, please do have an eye upon the following blogs as the best reference of this blog post;
- Get started using HDInsight Hadoop Tools for Visual Studio
- Get started with the HDInsight Emulator
- Develop C# Hadoop streaming programs for HDInsight
- Hadoop in HDInsight on Windows
Please do comment below to share your best practice.