Motivation:
It’s all about the different methods used in data science.

Data Science Methodology:
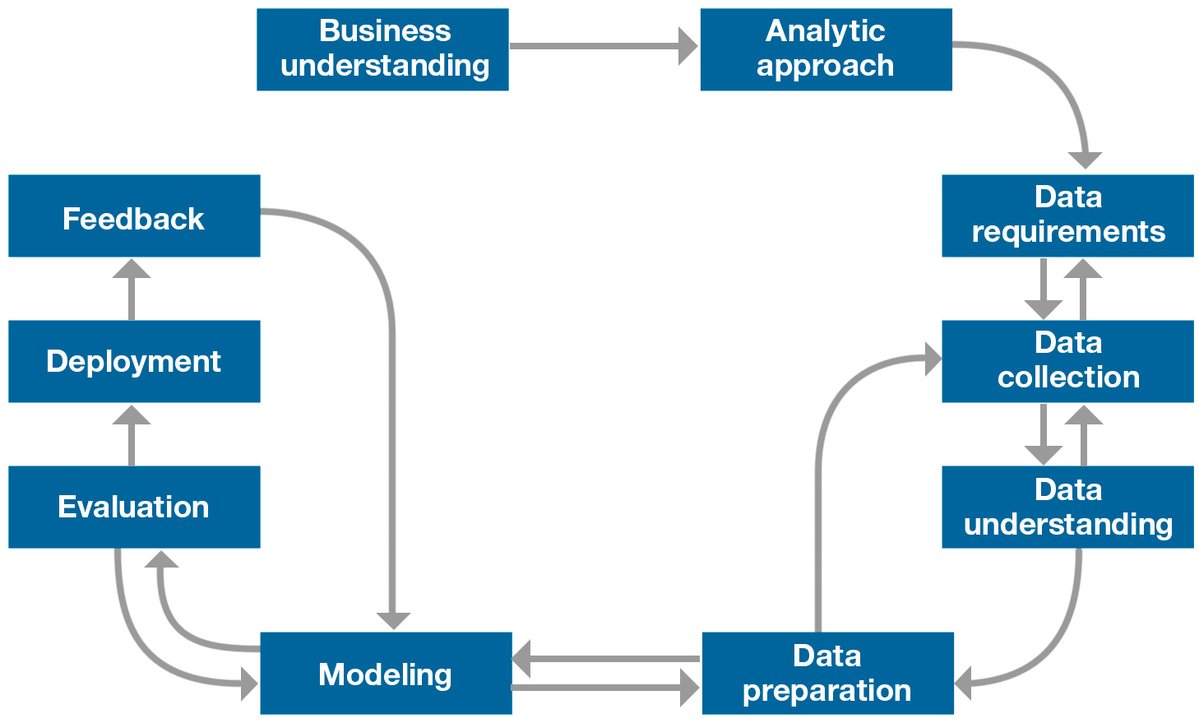
There is the following methodology used in data science which can further categories into different phases;
- From Problem to Approach
- Business Understanding
- Analytical Approach
- Working with Data
- Data Requirements
- Data Collection
- Data Understanding
- Data Preparation
- Deriving the Answer
- Modeling
- Evaluation
- Development
- Feedback
Let’s start understanding one by one;
From Problem to Approach;
- Business Understanding

It helps clarify the goal of the entity asking the question.
E.g. Say, We are interested in automating the process of figuring out the cuisine (style of cooking) of a given dish or recipe.
Let’s apply the business understanding stage to this problem.
So the questions will arise;
- Can we predict the cuisine of a given dish using the name of the dish only? The answer is definitely, NO!
- Following dish, names were taken from the menu of a local restaurant in Toronto, Ontario in Canada. “Beast”, “2 PM” and “4 Minute”
- Are you able to tell the cuisine of these dishes? Well, these’re the Japanese dishes, definitely somebody sitting in Islamabad cannot tell that.
- What about by appearance only? Well, No, especially when it comes to countries in close geographical proximity such as Scandinavian countries, or Asian countries.
* At this point, we realize that automating the process of determining the cuisine of a given dish is not a straightforward problem as we need to come up with a way that is very robust to the many cuisines and their variations.
- What about determining the cuisine of a dish based on its ingredients?
- Well, the answer is Potentially yes, as there are specific ingredients unique to each cuisine.
* As we guessed, yes determining the cuisine of a given dish based on its ingredients seems like a viable solution as some ingredients are unique to cuisines. For example:
- When we talk about “American” cuisines, the first ingredient that comes to one’s mind (or at least to my mind =D) is beef or turkey.
- When we talk about “British” cuisines, the first ingredient that comes to one’s mind is haddock or mint sauce.
- When we talk about “Canadian” cuisines, the first ingredient that comes to one’s mind is bacon or poutine.
- When we talk about “French” cuisines, the first ingredient that comes to one’s mind is bread or butter.
- When we talk about “Italian” cuisines, the first ingredient that comes to one’s mind is tomato or ricotta.
- When we talk about “Japanese” cuisines, the first ingredient that comes to one’s mind is seaweed or soy sauce.
- When we talk about “Chinese” cuisines, the first ingredient that comes to one’s mind is ginger or garlic.
- When we talk about “Pakistani” cuisines, the first ingredient that comes to one’s mind is chicken, masala or chillis.
Accordingly, can we determine the cuisine of the dish associated with the following list of ingredients?

Its Pakistani since the recipe is most likely of a Chicken Biryani.
- Analytical Approach
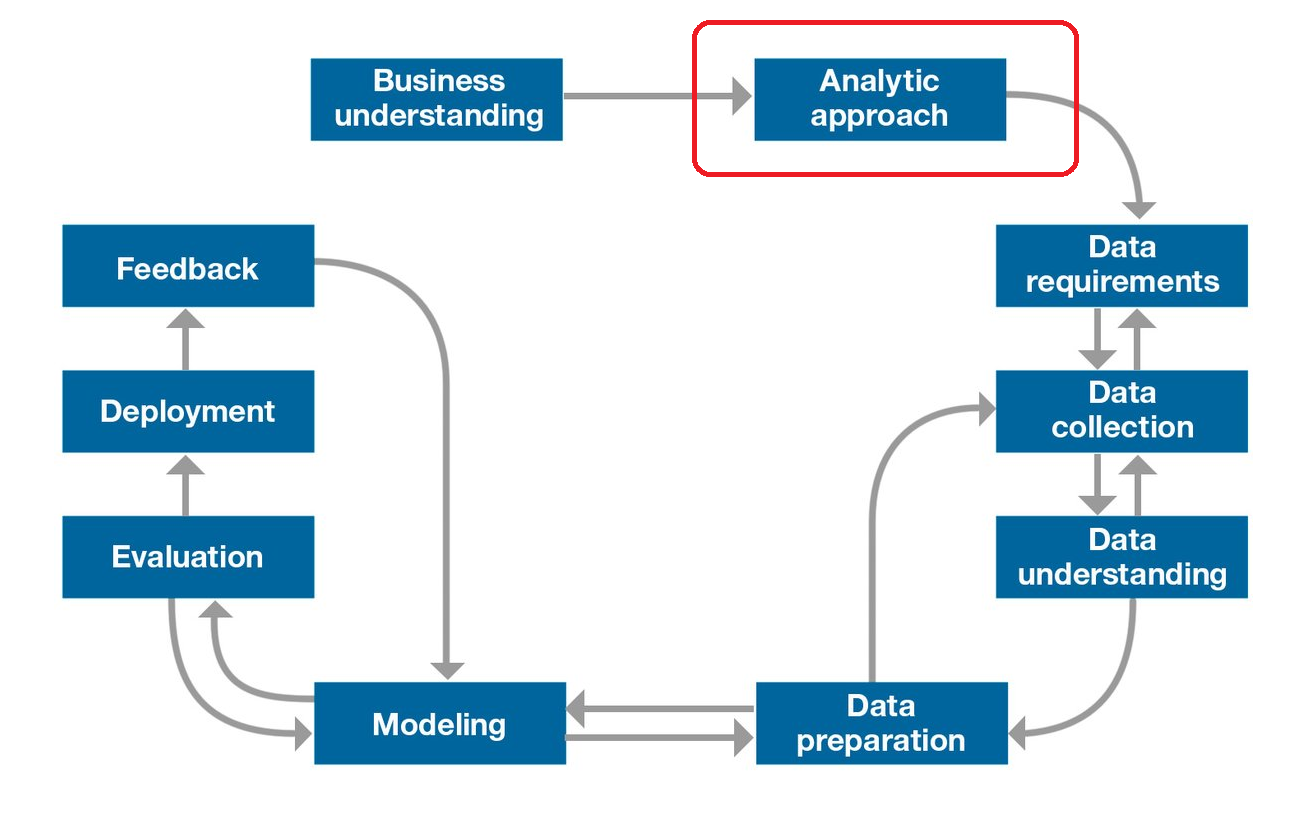
So why are we interested in data science? Once the business problem has been clearly stated, the data scientist can define the analytic approach to solve the problem. This step entails expressing the problem in the context of statistical and machine-learning techniques so that the entity or stakeholders with the problem can identify the most suitable techniques for the desired outcome.
Why is the analytic approach stage important? Because it helps into definity what type of patterns will be needed to address the question most effectively.
E.g. Let’s explore a machine learning algorithm, decision trees, and see if it is the right technique to automate the process of identifying the cuisine (style of cocking) of a given dish or recipe while simultaneously providing us with some insight on why a given recipe is believed to belong to a certain type of cuisine.
This is a decision tree that a naive person might create manually. Starting at the top with all the recipes for all the cuisines in the world, if a recipe contains rice, then this decision tree would classify it as Japanese cuisine. Otherwise, it would be classified as not a Japanese cuisine.
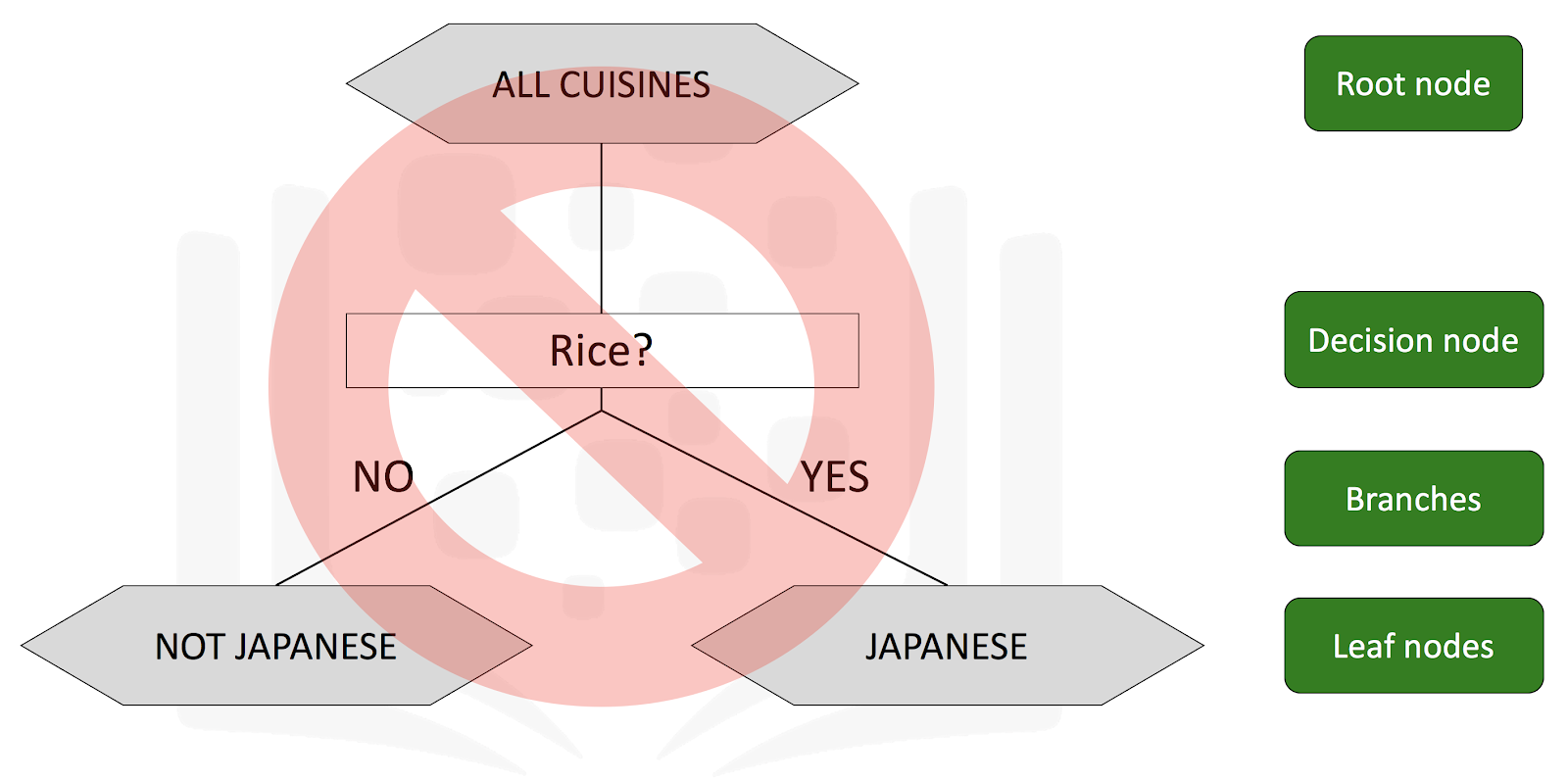
Is this a good decision tree? No, because a plethora (a large or excessive amount) of dishes from other cuisines contain rice. Therefore, using rice as the ingredient in the Decision node to split on is not a good choice.
Decision Trees;
In order to build a very powerful decision tree for the recipe case study, let’s take some time to learn more about decision trees.
- Decision trees are built using recursive partitioning to classify the data.
- When partitioning the data, decision trees use the most predictive feature (an ingredient in this case) to split the data.
- Predictiveness is based on a decrease in entropy – gain in information, or impurity.
Suppose that our data is comprised of green triangles and red circles.
The following decision tree would be considered the optimal model for classifying the data into a node for green triangles and a node for red circles.

Each of the classes in the leaf nodes is completely pure – that is, each leaf node only contains data points that belong to the same class.
On the other hand, the following decision tree is an example of the worst-case scenario that the model could output.

Each leaf node contains data points belonging to the two classes resulting in many datapoints ultimately being misclassified.
A tree stops growing at a node when:
- Pure or nearly pure.
- No remaining variables on which to further subset the data.
- The tree has grown to a preselected size limit.
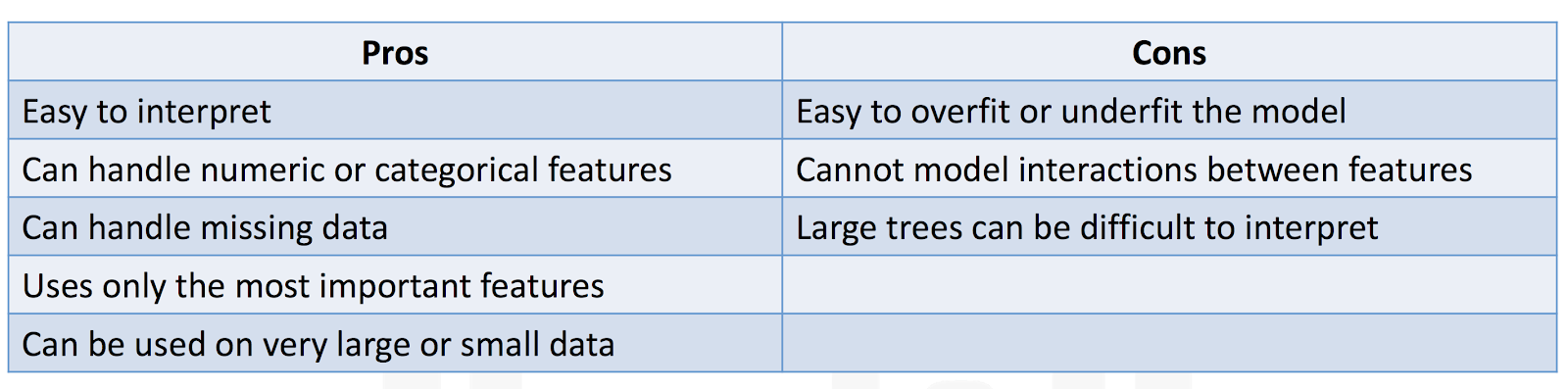
Here are some characteristics of decision trees:
Now let’s put what we learned about decision trees to use. Let’s try and build a much better version of the decision tree for our recipe problem.

I hope you agree that the above decision tree is a much better version than the previous one. Although we are still using Rice as the ingredient in the first decision node, recipes get divided into Asian Food and Non-Asian Food. Asian Food is then further divided into Japanese and Not Japanese based on the Wasabiingredient. This process of splitting leaf nodes continues until each leaf node is pure, i.e., containing recipes belonging to only one cuisine.
Accordingly, decision trees is a suitable technique or algorithm for our recipe case study.
From Requirements to Collection

- Data Requirements
Check, what are the data requirements?
E.g. If a problem is a dish, then data is an ingredient. A data requirement is the initial set of ingredients.
- Data Collection
Check, what occurs during the data collection? Gather available data.

In the initial data collection stage, data scientists identify and gather the available data resources. These can be in the form of structured, unstructured, and even semi-structured data relevant to the problem domain.
Defining the Inaccessible data. E.g. Data Wanted but not available.
Data scientist determine how to prepare the data. He identifies the data that is required for data modeling. He determines how to collect the data.
From Understanding to Preparation
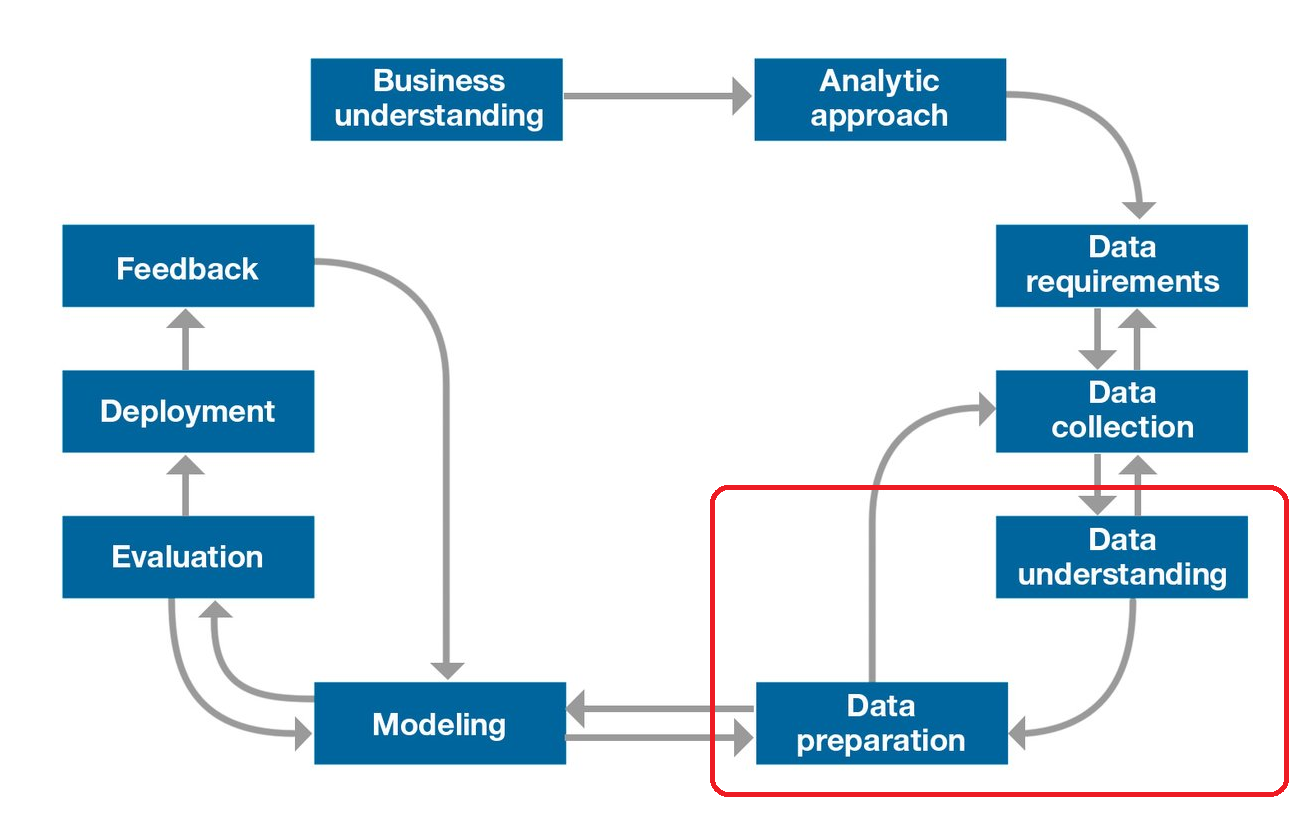
- Data Understanding
Like, What does it mean to “prepare” or “clean” data?
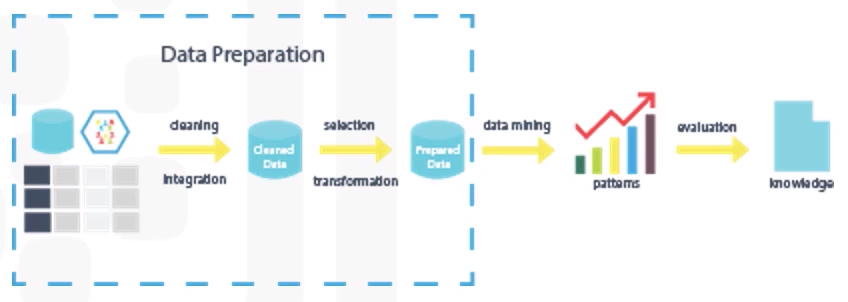
- Understanding of data, like descriptive statistics
- Univariable Statistics
- Pairwise corrections
- Histogram – Are good way to understand how values or variables are distributed, and what sorts of data preparation may be needed to make the variable more useful in a model.
- Looking at data quality, like Data quality
- Missing Values
- Invalid or misleading values
- This is an iterative process
- Iterative data collection and understanding.
Data understanding encompasses all activities related to constructing the dataset.
- Data Preparation
Like, What are ways in which data is prepared? This is the most time-consuming phase. Like 70% to 90% of overall project time. Automation some of data collection and preparation process in the code/database can reduce this time up to 50%.
Its simply like cleaning of data or removing useless stuff. Its all about the transforming data.
Feature engineering is also the part of data preparation. It is the process of using domain knowledge of the data to create features that make the machine learning algorithms work. Feature engineering is critical when machine learning tools are being applied to analyze the data.
Data scientist need to make sure to pay attention to the detail in this area. After all, it takes just one bad ingredient to ruin a fine meal.
Here prepare data for the next stage of modeling. This stage involves exploring the data further and making sure that it is in the right format for the machine learning algorithm that we selected in the analytic approach stage, which is decision trees.
We simply make our observations and fix the problems in the data to learn the data better and note any interesting preliminary observations.
It involves the following;
- Data preparation involves properly formatting the data.
- Data preparation involves correcting invalid values and addressing outliers.
- Data preparation involves removing duplicate data.
- Data preparation involves addressing missing values.
During data preparation, data scientists and DBAs identify missing data. They determine the timing of events. They aggregate the data and merge them from different sources. They define the variables to be used in the model.
From Modeling to Evaluation

- Data Modeling
Like, Sampling the food, I mean sampling the data. And see if it is appropriate or in need of more seasoning.
In what day data can be visualized to get to the answer that is required.

Data Modeling focus on developing models that are either predictive or destructive.
- Descriptive Model; An example of a descriptive model might examine things like: if a person did this, then they’re likely to prefer that.
- Predictive Model; A predictive model tries to yield yes/no, or stop/go type outcomes.
These models are based on the analytic approach that was taken, either statistically driven or machine learning driven.
The data scientist will use a training set for predictive modeling.

A training set is a set of historical data in which the outcomes are already known. The training set acts like a gauge to determine if the model needs to be calibrated. In this stage, the data scientist will play around with different algorithms to ensure that the variables in play are actually required.
The success of data compilation, preparation, and modeling, depends on the understanding of the problem at hand, and the appropriate analytical approach being taken.
The data support the answering of the question and like the quality of the ingredients in cooking, sets the stage for the outcome. Constant refinement, adjustments, and tweaking are necessary within each step to ensure the outcome is one that is solid.
In descriptive Data Science Methodology, the framework is geared to do 3 things:
- Understand the question at hand.
- Select an analytic approach or method to solve the problem.
- Obtain, understand, prepare, and model the data.
The end goal is to move the data scientist to a point where a data model can be built to answer the question.
E.g. With dinner just about to be served and a hungry guest at the table, the key question is: Have I made enough to eat? Well, let’s hope so.
In this stage of the methodology, model evaluation, deployment, and feedback loops ensure that the answer is near and relevant. This relevance is critical to the data science field overall, as it ís a fairly new field of study, and we are interested in the possibilities
it has to offer. The more people that benefit from the outcomes of this practice, the further the field will develop.
- Data Evaluation
Like, Does the model used really answer the initial question or does it need to be adjusted.
A model evaluation goes hand-in-hand with the model building as such, the modeling and evaluation stages are done iteratively. Model evaluation is performed during model development and before the model is deployed. Evaluation allows the quality of the model to be assessed but it’s also an opportunity to see if it meets the initial request. Evaluation answers the question: Does the model used really answer the initial question or does it need to be adjusted?
Model evaluation can have two main phases.
Diagnostic Measures; which is used to ensure the model is working as intended.
- Predictive Model; If the model is a predictive model, a decision tree can be used to evaluate if the answer the model can output, is aligned to the initial design. It can be used to see where there are areas that require adjustments.
- Descriptive Model; If the model is a descriptive model, one in which relationships are being assessed, then testing set with known outcomes can be applied, and the model can be refined as needed.
Statistical Significance; The second phase of evaluation that may be used is statistical significance testing.

This type of evaluation can be applied to the model to ensure that the data is being properly handled and interpreted within the model. This is designed to avoid unnecessary second-guessing when the answer is revealed. So now, let’s go back to our case study so that we can apply the “Evaluation” component within the data science methodology.
So, how do we determine which model was optimal? By plotting the true-positive rate against the false-positive rate for different values of the relative misclassification cost, the ROC curve helped in selecting the optimal model.
E.g. To evaluate our model of Asian and Pakistani cuisines, we will split our dataset into a training set and a test set. We will build the decision tree using the training set. Then, we will test the model on the test set and compare the cuisines that the model predicts to the actual cuisines.
From Development to Feedback

- Development
Like, are stakeholders familiar with the new tool.
While a data science model will provide an answer, the key to making the answer relevant and useful to address the initial question, involves getting the stakeholders familiar with the tool produced.
In a business scenario, stakeholders have different specialties that will help make this happen, such as the solution owner, marketing, application developers, and IT administration.
Once the model is evaluated and the data scientist is confident it will work, it is deployed and put to the ultimate test.
Depending on the purpose of the model, it may be rolled out to a limited group of users or in a test environment, to build up confidence in applying the outcome for use across the board.
- Feedback
Like, problem solved,? Question answered?
The value of the model will be dependent on successfully incorporating feedback and making adjustments for as long as the solution is required. Throughout the Data Science Methodology, each step sets the stage for the next. Making the methodology cyclical, ensures refinement at each stage in the game.
The feedback process is rooted in the notion that, the more you know, the more that you’ll want to know.
Once the model is evaluated and the data scientist is confident it’ll work, it is deployed and put to the ultimate test: actual, real-time use in the field.

Data collection was initially deferred because the data might not readily available at the time. But after feedback and practical experience with the model, it might be determined that adding that data could be worth the investment of effort and time.
We also have to allow for the possibility that other refinements might present themselves during the feedback stage. Also, the intervention actions and processes would be reviewed and very likely refined as well, based on the experience and knowledge gained through initial deployment and feedback.
Finally, the refined model and intervention actions would be redeployed, with the feedback process continued throughout the life of the Intervention program.
Conclusion:
So this is all about the Data Science Methodology. One who reviewed each method with complete focus would have the data science methodology on his fingertips.
* The Blog post was compiled with the help of the data science methodology course available at Cognitive class. It is highly recommended to review the course from here; https://cognitiveclass.ai/courses/data-science-methodology-2/